QuackingDuck: Using OpenAI's ChatGPT as Natural Language Interface for DuckDB
TL;DR
I built a small demo of a natural language interface for DuckDB using OpenAI’s ChatGPT API, called QuackingDuck.
Based on a natural language question, QuackingDuck will generate an SQL query, execute it against DuckDB, and return a natural language answer and a Pandas DataFrame containing the result set.
You can find a self-contained Colab notebook of QuackingDuck here.
Introduction
About a year ago I evaluated OpenAI’s GPT-3 in the context of
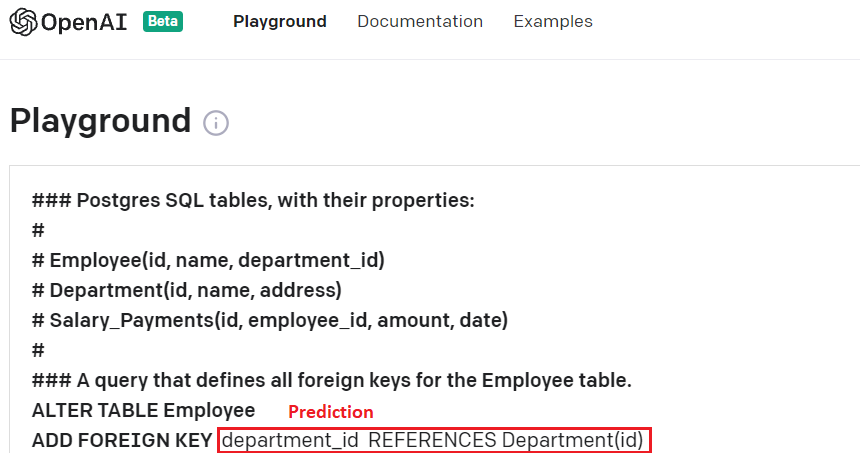
With code-davinci-002, which is part of the GPT-3.5 model family, I achieved an accuracy of 0.811 on this task, for a random sample of 1000 schemas from GitSchemas. The results were surprisingly good for an off-the-shelf model that was not fine-tuned for this particular task. GPT-3.5 models appear to have a good understanding of SQL itself, but also of the concept of database tables and how they relate to the real world, which is essential for tasks like Text-to-SQL.
With the release of ChatGPT the internet was flooded with examples of people using it for all kinds of tasks, among others - as an assistant for writing SQL (“Can ChatGPT Write Better SQL than a Data Analyst?”, “Power Up Your MySQL Queries: How ChatGPT Can Help You Retrieve MySQL Data”, “Using ChatGPT AI artificial intelligence to write SQL queries” …). ChatGPT is a GPT-3.5 variant that was finetuned for a conversational setting using Reinforcement Learning with Human Feedback (RLHF), which makes it less dependent on clever prompt engineering than the original GPT-3.5 models and hence more accessible to end-users. Also, it seems to combine the strength of the previously separate text- and code-generation models (text-davinci-003 and code-davinci-002), which makes it more flexible.
One thing I was missing though with the ChatGPT SQL examples, was the direct integration with a database system. Instead of having to ask ChatGPT to write an SQL query, and copy-pasting it manually into my database client, it would be great to just ask ChatGPT a natural language question about my database, and it would simply answer it for me (either in natural language or with a result set that I can use for downstream tasks).
More generally, this falls under the term Retrieval-Enhancement, which is essentially the idea of enriching a large language model’s prompt or prediction with additional information from external sources such as knowledge graphs, vector databases or SQL databases. While libraries like LangChain and Llama Index offer a user-friendly abstractions for this concept, I wanted to build a small example from scratch to get a feel for how this works.
I started out with a combination of text-davinci-003 and code-davinci-002 models to get a working demo. But shortly after, OpenAI released the ChatGPT model for API users, and I switched to this model (aka gpt-3.5-turbo) altogether, which made it super easy to add an error-correction step that I will explain later on.
For the demo I chose DuckDB as database system, which is a lightweight and blazing-fast analytical database management system, that was originally developed at the Database Architectures group at CWI in Amsterdam, and is now maintained and further developed by DuckDB Labs. Since the database runs in-process and is installable with a simple pip install command, it makes it a perfect fit for a small self-contained demo.
Overview of QuackingDuck
The idea is to have a function ask(question="What is the average price of...", debug=False) that can be called to ask questions to a DuckDB database instance.
Internally, it should do the following:
(1) connect to a DuckDB database instance
(2) let the user write a question in natural language query
(3) let OpenAI’s GPT-3.5 model convert the question to SQL, given the schema of the database
(4) send the query to DuckDB and return the result as markdown (if the query results in an error, we do an error correction step, more on that in the prompting section)
(5) take the question together with the query result, and instruct OpenAI’s GPT-3.5 model to compose a natural language answer
When debug=True QuackingDuck will print the prompts and the SQL query it used to retrieve the result set. This makes it a bit easier to understand what’s going on under the hood.
For convenience, there is also an explain_content(details) function to give the user some general understanding of what kind of data in the database.
For this functionality, following steps should be performed:
(1) connect to a DuckDB database instance
(2) given the schema of the database, use GPT-3.5 to generate a detail="one sentence" summary of the overall content.
The level of detail of the content summary can be controlled with the details parameter, which is entirely free-text and will be part of the prompt. It could be, e.g., one sentence or one paragraph or in very much detail.
I find this concept of free-text parameters quite interesting, and I actually expect to see it more often in the future.
It will be interesting to see how we can protect systems from malicious users that try to exploit this (similar to SQL injection).
The following diagram provides an overview of the components of QuackingDuck:

That’s basically all there is to it. But let’s dive into the details, in particular the prompts.
Prompting
The novelty with the ChatGPT API is that in addition to the user prompt there is a also a context that can be given to the model. The context consists of (1) a system prompt that helps set the general behavior of the assistant, and (2) the previous conversation, which provides additional context to ChatGPT.
With the text-davinci-003 and code-davinci-002 models, I tried to cram all context information into the user prompt, which seemed to confuse the model at times. ChatGPT makes this much easier, as I can now provide the context separately, and the user prompt can be much more focused on the actual task at hand.
This has been particularly useful for the error correction step, where I can provide the previous SQL query as context, and simply ask ChatGPT to fix the query based on the error message from DuckDB. Since DuckDB’s error message are very specific, and sometimes even contain suggestions (“did you mean xyz?”) this works very well.
Below are all the prompts that QuackingDuck uses, including system prompts and contexts.
Schema Summary Prompt
Generate summary of the database schema
System prompt:
You are a helpful assistant that can generate a human redable summary of database content based on the schema.
User prompt:
SQL schema of my database:
table_name(column1: type, column2: type, ...)
first row:
| | column1 | column2 | ... |
|---:|----------:|----------:|-------|
| 0 | value1 | 1234 | ... |
table_name2(column1: type, column2: type, ...)
first row:
...
Explain in {detail} what the data is about.
Output example:
The database contains information about customers, laptops, PCs, printers, products, and sales.
Generate SQL Prompt
Generate SQL query. I use Postgresql is the prompt because its syntax is very similar to DuckDB’s, and it is probably much more prevalent in GPT’s training corpus.
Context:
System:
You are a helpful assistant that can generate Postgresql code based on the user input. You do not respond with any human readable text, only SQL code.
User:
{summary prompt}
Assistant:
{summary}
User prompt:
Output a single SQL query without any explanation and do not add anything to the query that was not part of the question.
Make sure to only use tables and columns from the schema above and write a query to answer the following question:
"{question}"
Output example:
SELECT model FROM laptops ORDER BY price DESC LIMIT 1;
Fix SQL Prompt
Revisit SQL query based on error message returned from DuckDB.
Context:
System:
You are a helpful assistant that can generate Postgresql code based on the user input. You do not respond with any human readable text, only SQL code.
User:
{summary prompt}
Assistant:
{summary}
User:
{sql_prompt}
Assistant:
{sql_query}
User prompt:
I got the following exception: {error}. Please correct the query and only print sql code, without an apology.
Output example:
SELECT model FROM laptops ORDER BY price DESC LIMIT 1;
Answer Question Prompt
Generate answer based on query result
Context:
System: You are a helpful assistant.
User:
{schema prompt}
Assistant:
{schema summary}
User:
{sql prompt}
Assistant:
{sql query}
User prompt:
Query Result:
{result_markdown}
Answer the question in natural language, based on information from the query result.
Output example:
The most expensive laptop is model number 2001.
Summary
This figure summarizes the flow of prompts and their contexts in QuackingDuck:

How to use it
You can find the sources of QuackingDuck in the following Colab notebook: here. The example database and example queries stem from a university-level SQL assignment (Yes, it passed!).
You can also run it yourself if you have an OpenAI account. All you need to do is to make a copy of the notebook and insert your OpenAI API key.
One .ask() call in the example notebook uses around 2k tokens that currently cost around 0.4 cents (gpt-3.5-turbo: $0.002 / 1K tokens).
Of course, you can also connect to your own instance of DuckDB, but you will need to change the connection string in the “Create a DuckDB Database” part of the notebook. Be aware that parts of your data can/will be sent to OpenAI’s servers as part of the prompts.
Conclusion
Overall, I found this an interesting learning experience, and I am quite happy with the result. My feeling is that this is a great tool for people new to SQL databases and SQL queries, as it can help them to get started without having to learn the syntax first.
For other use cases, I think it is important to keep the following limitations in mind:
1) The dependency to OpenAI means that using QuackingDuck is not entirely free and relies on a closed model on OpenAI’s servers. That also implies that data is sent as part of the prompt to OpenAI’s servers, which makes the solution unsuitable for privacy or IP-sensitive use cases.
2) Large Langauge Models such as GPT-3.5/ChatGPT tend to hallucinate answers when they are uncertain, which means they can give answers very confidently, while being completely wrong (see ChatGPTs limitation section). Not that all humans are any better at this. Still, this makes it impossible to fully rely on QuackingDucks output, and requires some manual double-checking of what happens under the hood.
One potential direction to overcome these limitations could lie in using smaller and open models, fine-tuned for particular sub-tasks. For a promising benchmark of fine-tuned T5 models vs. OpenAI’s models on the Text-to-SQL tasks, I recommend taking a look at the following paper Evaluating the Text-to-SQL Capabilities of Large Language Models, Rajkumar et al., 2022.